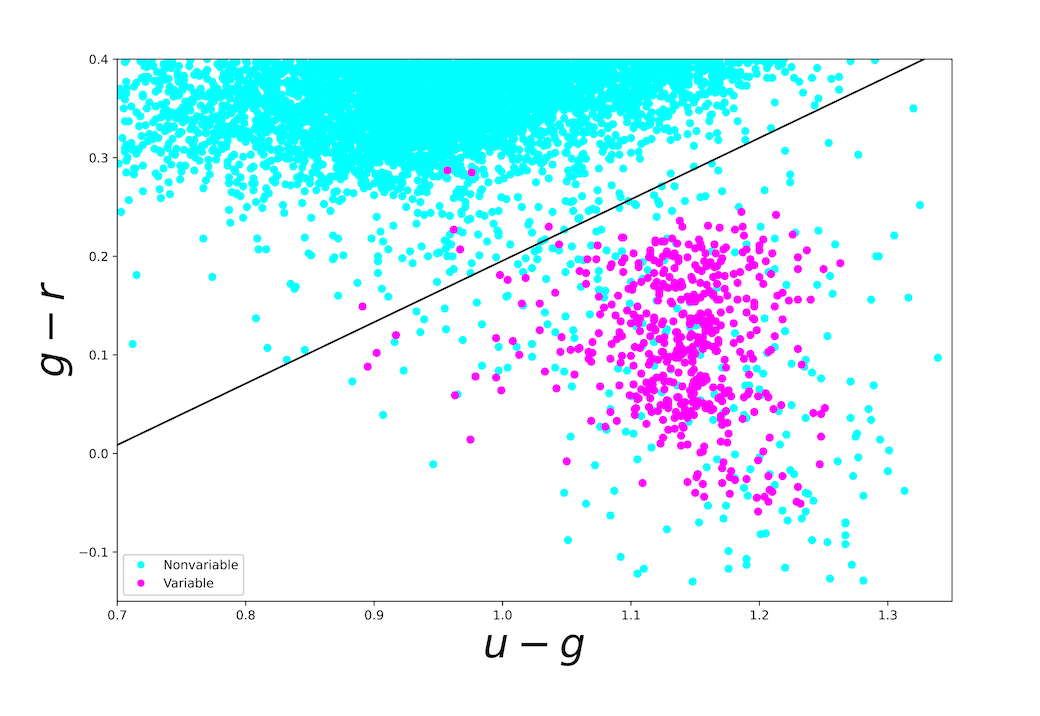
El método de clasificación de regresión logística se utiliza para separar estrellas variables de estrellas no variables. Los puntos de color azul claro indican fuentes no variables, mientras que los morados indican fuentes variables. El límite de clasificación está indicado por la línea negra. La regresión logística logra una precisión de 0,969 y una puntuación F1 de 0,628.
La clasificación es una tarea popular en el aprendizaje automático (ML) y la inteligencia artificial (AI), y ocurre cuando los resultados son variables categóricas. Hay una amplia variedad de modelos que intentan sacar conclusiones de los valores observados, por lo que los algoritmos de clasificación predicen las etiquetas de clase categóricas y las usan para clasificar nuevos datos.
La clasificación es una tarea popular en el aprendizaje automático (ML) y la inteligencia artificial (AI), y ocurre cuando los resultados son variables categóricas. Hay una amplia variedad de modelos que intentan sacar conclusiones de los valores observados, por lo que los algoritmos de clasificación predicen las etiquetas de clase categóricas y las usan para clasificar nuevos datos.
Los modelos de clasificación populares, incluidos la regresión logística, el árbol de decisiones, el bosque aleatorio, la máquina de vectores de soporte (SVM), el perceptrón multicapa, Naive Bayes y las redes neuronales, han demostrado ser efectivos y precisos aplicados a muchos problemas industriales y científicos.
En particular, la aplicación de ML a la astronomía ha demostrado ser muy útil para la clasificación, agrupación y limpieza de datos. Esto se debe a que después de aprender a usar las computadoras, estas tareas pueden realizarlas automáticamente con mayor precisión y rapidez que los operadores humanos.
Con esto en mente, en este artículo revisaremos algunos de estos populares algoritmos de clasificación y luego aplicaremos algunos de ellos a los datos de observación de estrellas no variables y estrellas variables RR Lyrae que provienen del sondeo SDSS. Con fines comparativos, calculamos la precisión y la puntuación F1 de los modelos aplicados.
Mohammad H. Zhoolideh Haghighi
Comentarios: Actas basadas en las conferencias impartidas durante el taller práctico de la Reunión de Astronomía ICRANet-ISFAHAN, que se publicarán en Astronomical and Astrophysical Transactions
Asignaturas: Instrumentación y Métodos para la Astrofísica (astro-ph.IM); Astrofísica solar y estelar (astro-ph.SR); Física Computacional (physics.comp-ph); Análisis de datos, estadísticas y probabilidades (physics.data-an)
Citar como: arXiv:2302.11573 [astro-ph.IM] (o arXiv:2302.11573v1 [astro-ph.IM] para esta versión)
https://doi.org/10.48550/arXiv.2302.11573
Enfócate para aprender más
Historial de envíos
Por: Mohammad Hossein Zhoolideh Haghighi
[v1] miércoles 22 de febrero de 2023 11:15:31 a. m. UTC (115 KB)
https://arxiv.org/abs/2302.11573
También te puede interesar
-
Nuevo descubrimiento: algas y bacterias se fusionan para formar un solo organismo en un laboratorio | Noticias científicas
-
Los astrónomos descubren 454 nuevos asteroides en el cinturón principal
-
Los biólogos moleculares han descifrado el código de la formina
-
La NASA Juno ve un lago de lava liso como el cristal en la luna Io de Júpiter
-
Llame a fotógrafos y astrónomos de Wicklow para obtener fotografías extraordinarias